A geração de áudio por inteligência artificial está passando por uma transformação importante: estamos saindo de arquiteturas em cascata para modelos totalmente end-to-end. Esse avanço resolve um problema clássico dos sistemas tradicionais de TTS (text-to-speech), que dependem da representação intermediária em espectrograma Mel — algo que frequentemente causa perda de informação e acúmulo de erros.
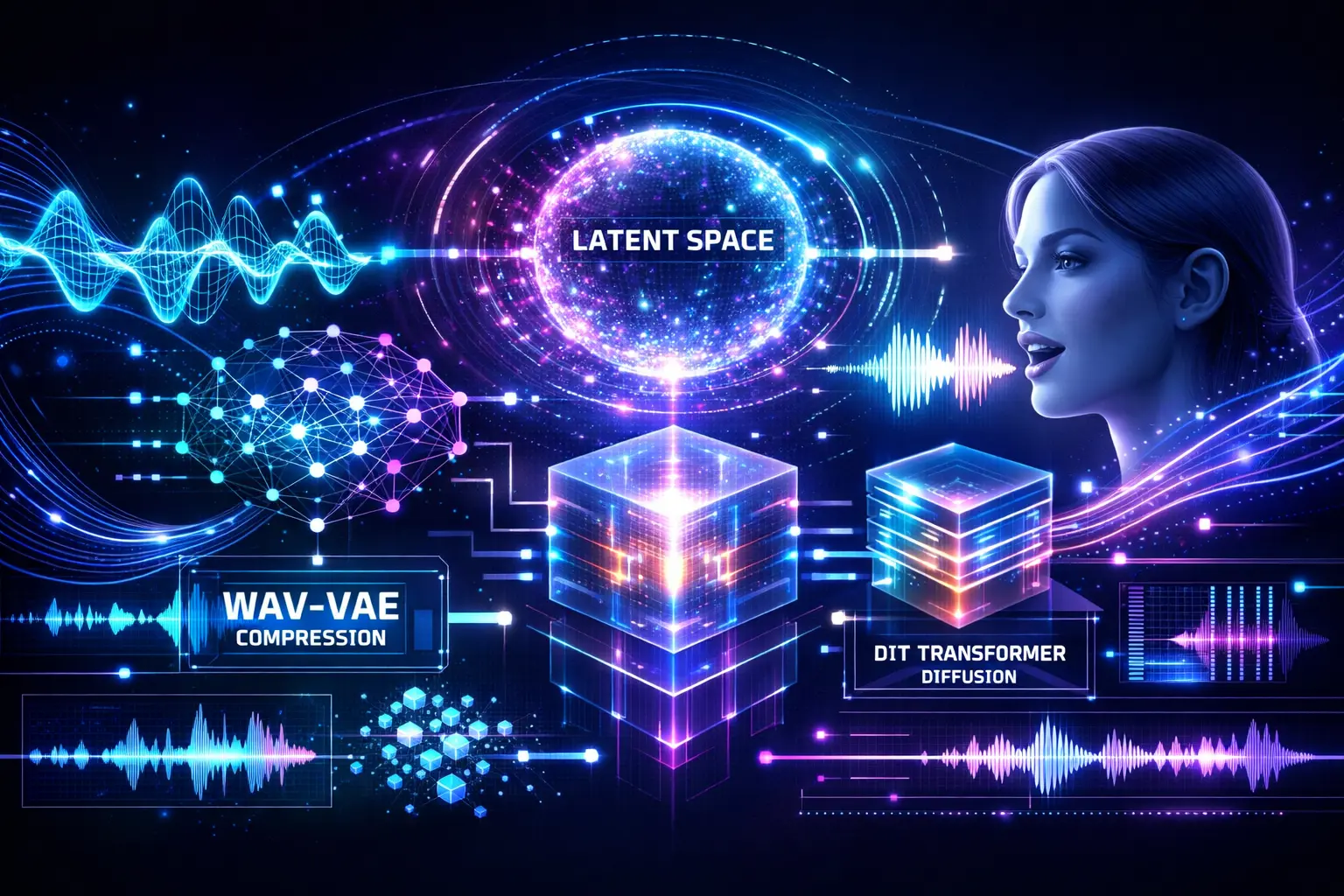
Nesse cenário, a equipe LongCat, da Meituan, acaba de lançar e open source o LongCat-AudioDiT, disponível em versões de 1B e 3.5B parâmetros. O modelo já está chamando atenção por redefinir o estado da arte em clonagem de voz zero-shot.
🚀 Uma nova arquitetura: sem espectrograma Mel
O grande diferencial do LongCat-AudioDiT é abandonar completamente o pipeline tradicional (previsão de características acústicas + vocoder). Em vez disso, ele adota uma arquitetura muito mais direta e eficiente:
- Wav-VAE (Variational Autoencoder de forma de onda)
- DiT (Diffusion Transformer)
Essa combinação permite modelar diretamente o áudio no espaço latente da forma de onda, reduzindo perdas e melhorando a qualidade final.
🔊 Wav-VAE: compressão extrema com alta fidelidade
O Wav-VAE utiliza uma arquitetura totalmente convolucional capaz de comprimir áudio de 24kHz em até 2000 vezes, reduzindo a taxa para apenas 11.7Hz.
Mesmo com essa compressão agressiva, o modelo mantém:
- Estrutura temporal e espectral precisa
- Qualidade sonora natural
- Alta fidelidade perceptiva
Isso é possível graças a técnicas como:
- Ramificações não paramétricas (shortcut connections)
- Treinamento adversarial com múltiplos objetivos
🧠 DiT com reforço semântico
Outro ponto inovador está no uso do UMT5 como codificador de texto. O modelo combina:
- Embeddings originais das palavras
- Estados ocultos das camadas superiores
Essa fusão ajuda a recuperar detalhes fonéticos que normalmente se perdem em representações semânticas mais abstratas, melhorando significativamente a inteligibilidade da fala gerada.
⚙️ Melhorias na inferência: adeus, instabilidade de voz
Para garantir qualidade consistente, o modelo introduz duas melhorias importantes:
1. Mecanismo de dupla restrição
Corrige o problema clássico de inconsistência entre treino e inferência em modelos de TTS baseados em fluxo.
Resultado:
- Eliminação do “desvio de timbre” (voice drift)
- Maior estabilidade na voz gerada
2. APG (Adaptive Projection Guidance)
Substitui o tradicional CFG (Classifier-Free Guidance).
Benefícios:
- Filtra apenas os sinais realmente úteis para guiar a geração
- Evita saturação espectral
- Produz áudio mais natural e equilibrado
📊 Desempenho impressionante
Nos benchmarks da série Seed, o LongCat-AudioDiT apresenta resultados de ponta:
- Similaridade (SIM):
- 0.818 no Seed-ZH
- 0.797 no Seed-Hard
Superando modelos conhecidos como:
-
Seed-TTS
-
CosyVoice 3.5
-
MiniMax-Speech
-
Taxas de erro:
- WER em inglês: 1.50%
- CER em chinês (frases difíceis): 6.04%
🧩 Treinamento mais simples, resultados melhores
Um detalhe curioso: o modelo foi treinado em uma única etapa, usando apenas dados pré-processados via ASR (transcrição automática).
Mesmo assim, conseguiu superar modelos que utilizam pipelines complexos de múltiplas fases — o que mostra a eficiência da nova abordagem.
🌍 Open source disponível
Para quem quiser explorar ou usar o modelo, tudo já está disponível publicamente:
- GitHub: https://github.com/meituan-longcat/LongCat-AudioDiT
- HuggingFace: https://huggingface.co/meituan-longcat/LongCat-AudioDiT
💡 Conclusão
O LongCat-AudioDiT marca uma virada importante na geração de áudio por IA. Ao eliminar intermediários e modelar diretamente a forma de onda, ele consegue:
- Melhorar qualidade
- Aumentar estabilidade
- Simplificar o treinamento
Esse tipo de abordagem deve influenciar fortemente a próxima geração de sistemas de voz — desde assistentes virtuais até criação de conteúdo, games e metaverso.
Se essa tendência continuar, estamos cada vez mais próximos de vozes sintéticas indistinguíveis das humanas.