No universo da visão computacional, fazer com que a IA observe uma imagem como um ser humano — percebendo e descrevendo cada detalhe — sempre foi um grande desafio. Mas isso pode estar mudando.
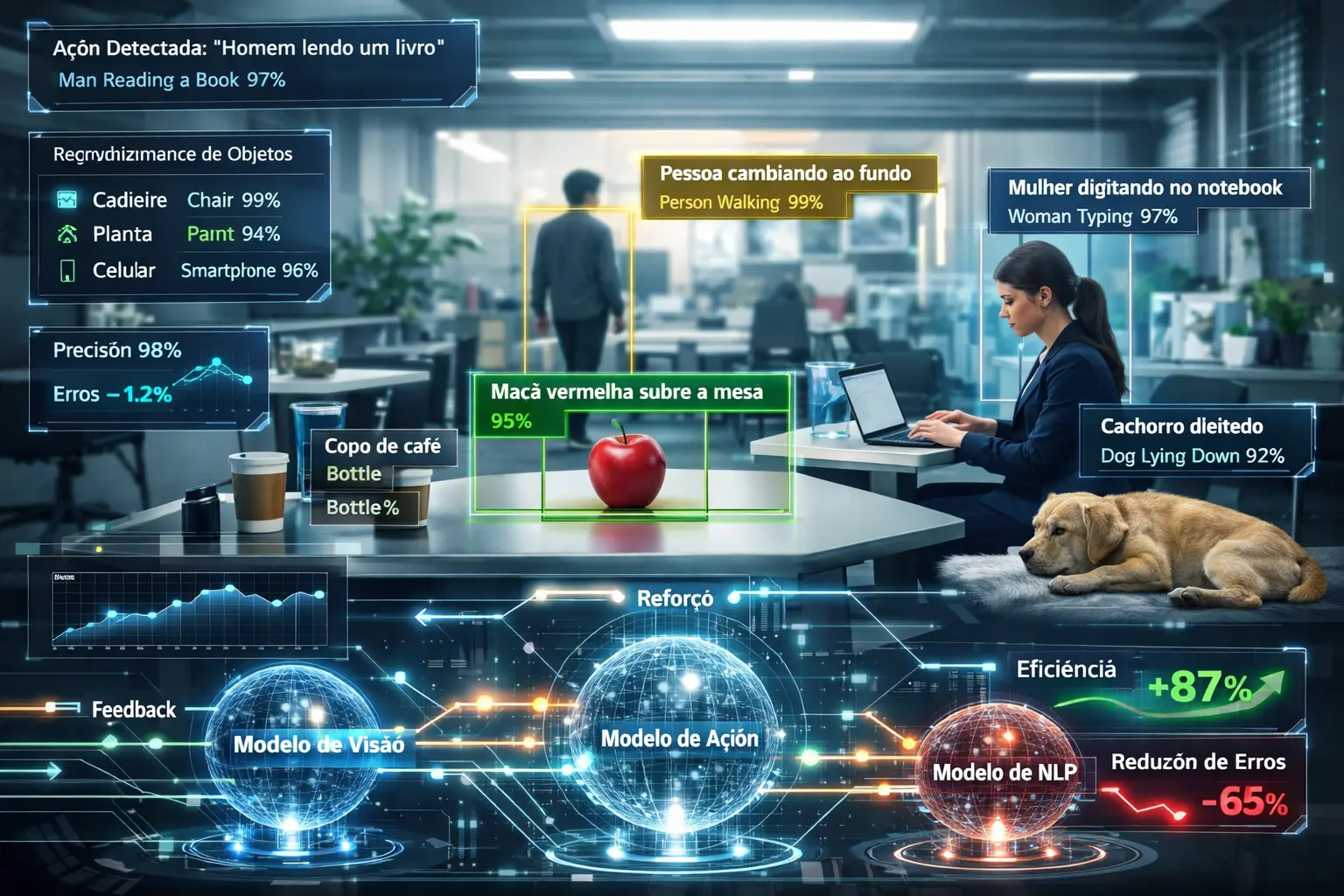
Recentemente, a Apple, em parceria com a Universidade de Wisconsin-Madison, apresentou um novo framework de treinamento chamado RubiCap, focado em um conceito conhecido como descrição densa de imagens.
O que é o RubiCap?
Diferente dos modelos tradicionais que geram descrições genéricas, o RubiCap foi criado para capturar detalhes específicos da imagem. Em vez de dizer apenas “uma mesa com frutas”, ele consegue identificar algo como “uma maçã vermelha sobre a mesa” ou “uma pessoa caminhando ao fundo”.
Esse nível de precisão aproxima a IA da forma como humanos realmente interpretam imagens.
Como funciona o treinamento?
O grande diferencial do RubiCap está no uso inteligente de aprendizado por reforço com múltiplos modelos trabalhando juntos:
- GPT-5 e Gemini 2.5 Pro geram diferentes descrições para a mesma imagem
- O Gemini 2.5 Pro também define critérios de avaliação
- O modelo Qwen2.5 atua como um “juiz”, avaliando a qualidade das descrições
Esse sistema cria um ciclo de feedback estruturado, permitindo que o modelo aprenda com mais precisão — corrigindo erros e evitando “alucinações” (informações incorretas).
Menos parâmetros, mais eficiência
Um dos pontos mais impressionantes do RubiCap é que ele prova que tamanho não é tudo quando se trata de IA.
Os modelos da família RubiCap variam entre 2 bilhões e 7 bilhões de parâmetros, mas mesmo assim apresentam resultados surpreendentes:
- O modelo de 7 bilhões de parâmetros alcançou o melhor desempenho geral
- Ele teve menos erros de “alucinação” do que modelos muito maiores (com até 72 bilhões de parâmetros)
- Em alguns casos, a versão de 3 bilhões de parâmetros superou a de 7 bilhões
Isso mostra que um bom método de treinamento pode ser mais importante do que simplesmente aumentar o tamanho do modelo.
Por que isso importa?
Essa abordagem traz benefícios claros:
- Redução de custos (menos necessidade de modelos gigantes)
- Maior precisão nas descrições
- Menos erros e informações inventadas
- Mais eficiência para aplicações reais
Na prática, isso pode impactar áreas como:
- Acessibilidade (descrição de imagens para deficientes visuais)
- Segurança (análise de imagens e detecção de riscos)
- E-commerce (descrições automáticas de produtos)
- Sistemas de vigilância e análise urbana
O futuro da visão computacional
O RubiCap reforça uma tendência importante: o futuro da IA não depende apenas de modelos maiores, mas de estratégias de treinamento mais inteligentes.
Ao combinar múltiplos modelos e usar feedback estruturado, a Apple e seus parceiros mostraram que é possível alcançar resultados superiores com menos recursos.
E isso pode ser apenas o começo.